Where are some corporate AI hubs?
Some Context: Digital Intelligence Index
The Digital Intelligence Index by Fletcher School / Tufts University is nice context information for this little research (data source: https://digitalintelligence.fletcher.tufts.edu/trajectory). They gathered a wide array of secundary data sources per country, aggregated into clusters, components, drivers and final scores rescaled from 0 to 100, estimating how overall digitally mature a nations economy is.
In particular, their scoring for the scorecard component innovation and change is interesting, because AI startups are part of that.
Innovation Momentum might indicate the near future, whereas overall digital innovative indicator signals the current state.
This is more a set of negative indicators, i.e. scoring low means there is properly not a lot of AI startup activity to find in that location. Arguably, the high performers might be more likely to have some AI business activity and possess a mature business ecosystem for AI companies, so this is where we will try to collect data.
pacman::p_load(tidyverse, tmap, openxlsx, sf, tidytable, data.table, tidytext, arrow, rvest, reclin, maps, mapview)
dindex <- openxlsx::read.xlsx("https://sites.tufts.edu/digitalplanet/digitalintelligence/DIIData2020", sheet = "Digital Evolution Main", startRow = 2)
data("World")
World2 <- left_join(World, dindex %>% select(Entity, `Overall Digital Evolution`=Innovation.and.Change.Zone, `Digital Evolution Rank`=Digital.Evolution.Score.Rank, `Digital Evolution Momentum (Rank)`=Innovation.and.Change.Momentum.Rank, `Innovativeness Rank` =Innovation.and.Change.Score.Rank, Innovation.and.Change.Score, `Innovation Momentum Indicator` = Innovation.and.Change.Momentum, iso_a3=ISO3C))## Joining, by = "iso_a3"World2 <- st_sf(World2)
tm_shape(World2) +
tm_polygons(col = "Digital Evolution Momentum (Rank)",
legend.hist = TRUE, palette = "seq", style = "order") +
tm_layout(legend.outside = F, aes.palette = list(seq = "-RdBu"))## Warning: Histogram not supported for styles "cont" or "order"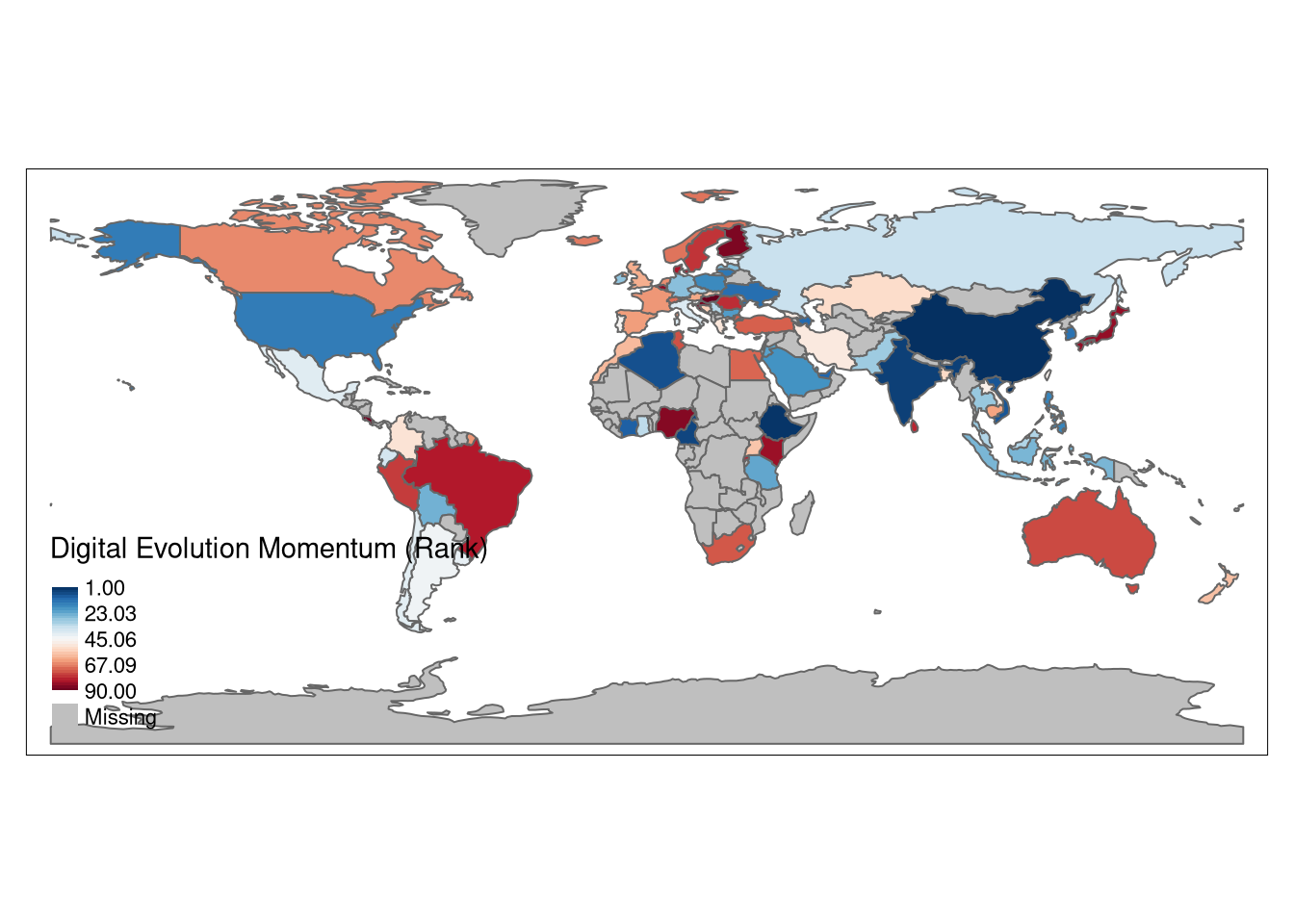
tm_shape(World2) +
tm_polygons(col = "Innovativeness Rank",
# style = "kmeans",
legend.hist = TRUE, palette = "RdGy") +
tm_layout(legend.outside = F)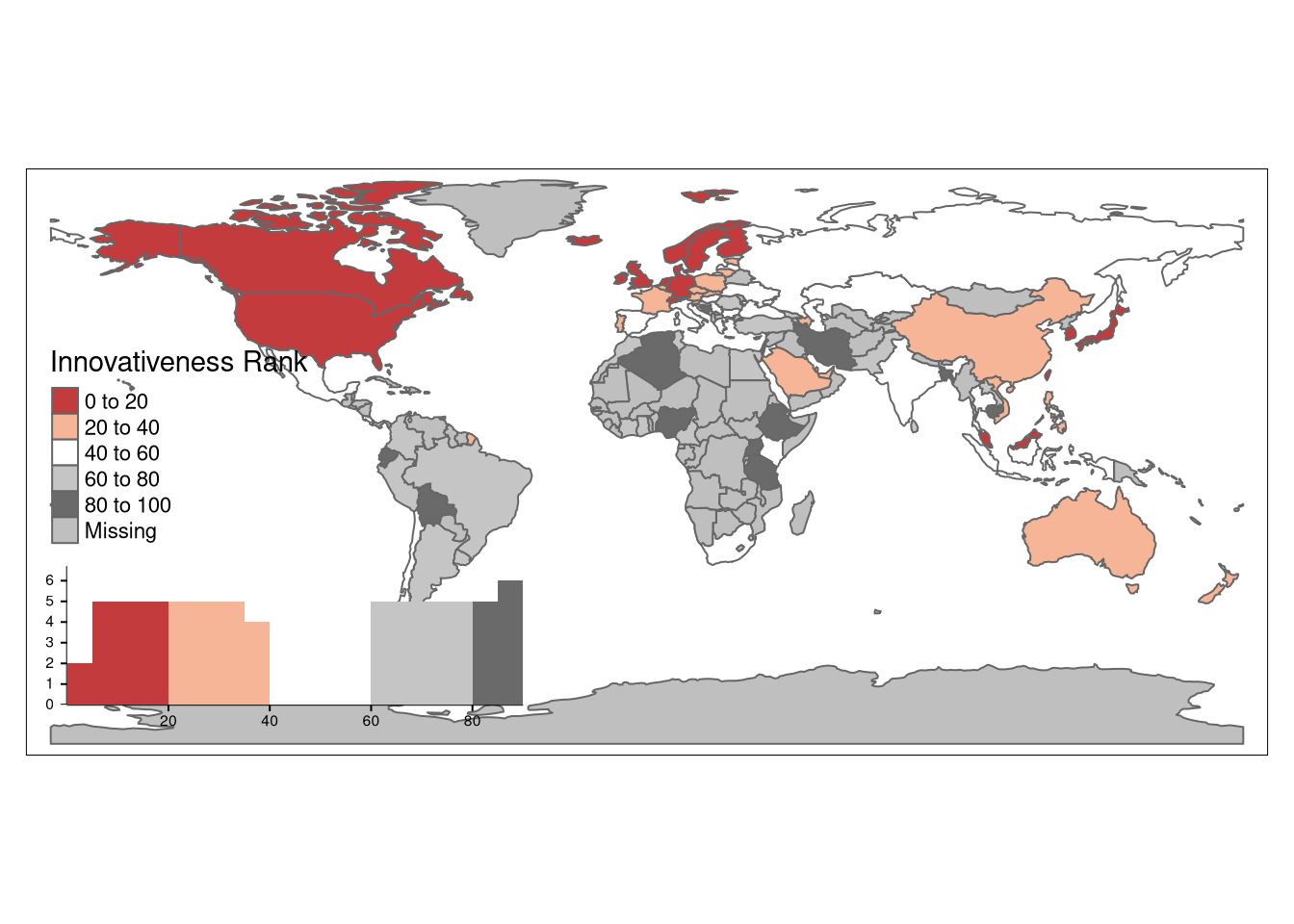
Overall Digital Maturity and Potential
Example places where one might expect to find mature and thriving AI hubs:
- USA
- Germany, Poland, Ireland
- China
AI company locations
I scraped a few datasets about AI startup and AI company locations. Let’s first find out where AI hubs are. Because the talent concentrates there, we can use this to narrow down our search for AI startup hubs.
ai_companies <- fread("/run/media/knut/HD/MLearningAlgoTests/aicompanies.csv")
ai_companies %>% select(company, website, location) %>% sample_n(10)## company website
## 1: Cyber Surgery https://cyber-surgery.com
## 2: Oneclick.Ai http://www.oneclick.ai
## 3: Journi http://journiapp.com
## 4: Talus Bioscience https://www.talus.biohttp://talus.bio
## 5: Overwatch Imaging http://www.overwatchimaging.com
## 6: Augury (company) https://www.augury.com/https://augury.com
## 7: Synap https://synap.ac/
## 8: TripGuru http://tripguru.io
## 9: PrepFlash http://www.prepflash.com
## 10: Sticky Technology http://stickytechnology.net/spiralvortex
## location
## 1: San Sebastián
## 2: Bellevue, Washington
## 3: ViennaAustria
## 4: Seattle
## 5: Hood River, Oregon
## 6: New York CityNew York
## 7: Leeds
## 8: London
## 9: Austin, TexasCollege Station, Texas
## 10: Mexico CityLocations column need some work.
source("/home/knut/Documents/clean.R")
ai_companies <- ai_companies %>% mutate(location=clean(str_squish(str_replace_all(location, '([[:upper:]])', ' \\1')))) %>% separate_rows(location, sep = "([[:upper:]])") %>% unnest_ngrams("ngram", "location", n_min = 1, drop = F)
cities <- fread("https://gist.githubusercontent.com/curran/13d30e855d48cdd6f22acdf0afe27286/raw/0635f14817ec634833bb904a47594cc2f5f9dbf8/worldcities_clean.csv") %>% mutate(location=tolower(city)) %>% select(location, country, population) %>% arrange(location, desc(population))
cities <- cities[!duplicated(location)] %>% select(-population)
ai_companies <- ai_companies %>% inner_join(cities) %>% select(-ngram) %>% distinct()## Joining, by = "location"print(c(nrow(ai_companies), nrow(fread("/run/media/knut/HD/MLearningAlgoTests/aicompanies.csv"))))## [1] 3508 12487The database has 3.5k records after cleaning, but of a total of 12k records. Let’s take a look which countries have the most AI companies according to this source:
ggcharts::bar_chart(ai_companies, country, top_n = 30)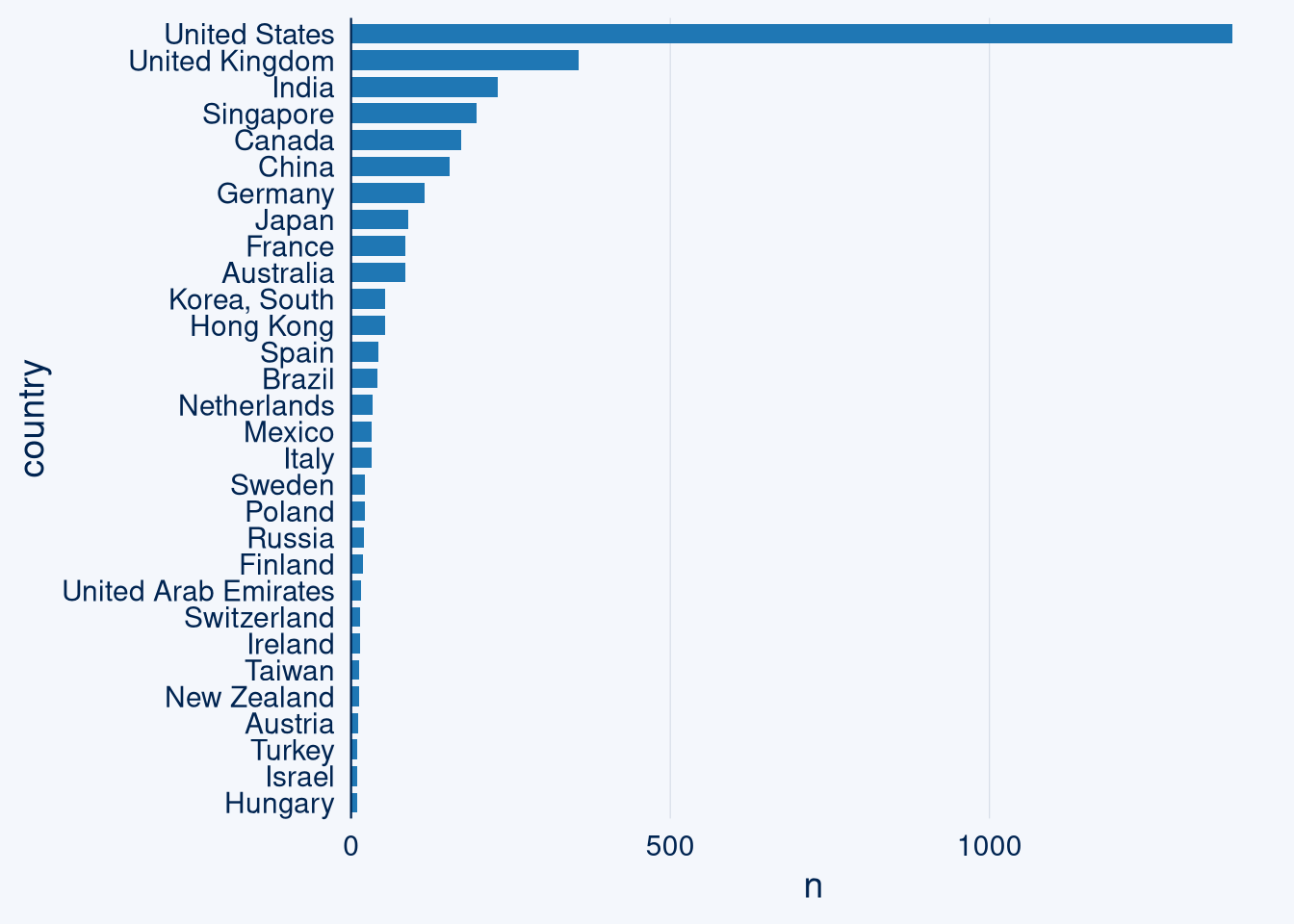
There is more in here. I’m forcing myself to do a quick and dirty job, not exhaustive information extraction. It’s just a blog post.
kg_names <- read_parquet("/run/media/knut/HD/MLearningAlgoTests/data/polar/w5mentities.parquet") %>% separate.(label, c("selector", "disambiguation"), sep = "[(]") %>% mutate.(disambiguation=str_remove(disambiguation, "[)]"))
kg_names_locations <- kg_names %>% right_join.(cities%>% mutate(nchar=nchar(location)) %>% filter(nchar>3) %>% mutate.(selector=location)) %>% left_join.(kg_names %>% select.(wikientity, spelling=selector) %>% mutate.(spelling=str_squish(spelling))) %>% distinct.() %>% mutate(nchar2=nchar(spelling)) %>% filter(nchar2>3)
kg_names_locations[is.na(kg_names_locations$spelling),"spelling"] <- kg_names_locations[is.na(kg_names_locations$spelling),"selector"]
chinese_cities_spellings <- read_html("https://en.wikipedia.org/wiki/List_of_cities_in_China") %>% html_node("table.selected_now") %>% html_table() %>% select(location=City, spelling=Chinese) %>% mutate(location=tolower(location), country="China")
kg_names_locations <- kg_names_locations %>% select.(location, country, spelling) %>% bind_rows.(chinese_cities_spellings)
kg_names_locations <- kg_names_locations %>% distinct.()
websites_html <- arrow::read_parquet("/run/media/knut/HD/MLearningAlgoTests/aistartup2") %>% na.omit()
websites_html2 <- arrow::read_parquet("/run/media/knut/HD/MLearningAlgoTests/aicompanies_websites2") %>% na.omit()
websites_html <- bind_rows.(websites_html, websites_html2)
websites_ngrams <- websites_html %>% unnest_ngrams("ngram", body, n_min = 1)
locations_quick <- websites_ngrams %>% mutate(ngram=tolower(ngram)) %>% inner_join.(kg_names_locations %>% rename(ngram=spelling)) %>% rename(spelling=ngram) %>% distinct.()
suffix <- locations_quick %>% mutate(suffix=urltools::domain(source) %>% urltools::suffix_extract())
suffix <- suffix$suffix$suffix
locations_clean <- locations_quick %>% mutate(suffix=suffix)
country_codes <- read_html("https://www.sitepoint.com/complete-list-country-code-top-level-domains/") %>% html_table("td", header = F, trim = T) %>% as.data.frame()%>% filter(X1%in%c(".ai", ".io", ".com")==F) %>% rename(suffix=X1, Country=X2) %>% mutate(suffix=str_remove(suffix, ".")) %>% mutate(Country=str_replace(Country, "People's Republic of China", "China")) %>% mutate(Country=str_replace(Country, "United States of America", "United States"))## Warning: The `fill` argument of `html_table()` is deprecated as of rvest 1.0.0.
## An improved algorithm fills by default so it is no longer needed.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.locations_clean <- locations_clean %>% left_join.(country_codes)
locations_filter <- locations_clean %>% filter(suffix%in%c("co", "ai", "com", "net", "org")==F) %>% mutate(country=ifelse(suffix=="io", "United States", country)) %>% filter(country==Country)I am mostly interested in grabbing the address data from the small address boxes usually at the bottom of the website. As a simple heuristic, I parse all data with libpostal docker container, which can classify location strings as belonging to cities, streetnames etc. If the city is from the same country, I’ll add it to the data. I checked how often it is right with a sample. More than 90%, though there is some data loss, some companies are on multiple locations.
# docker run -d -p 8070:8080 clicksend/libpostal-rest Using a knowledge graph and other stuff to get a few more records out of here. These measures yield ca 3800 records, roughly 300 more, many new records from India, as shown below (only the new records).
parse_address <- function(address, source) {
prep_query <- function(x) {
paste0('{"query": "', x , '"}')
}
query <- prep_query(clean(address))
query %>%
purrr::map_dfr(~
httr::POST(url="localhost:8070/parser", body = .x) %>%
httr::content("text", encoding = "UTF-8") %>%
jsonlite::fromJSON() %>% mutate(source=source)
)
}
safeparse <- possibly(parse_address, otherwise = data.table(label=c(), value=c(), source=c()))
websites_html <- arrow::read_parquet("/run/media/knut/HD/MLearningAlgoTests/aistartup2") %>% na.omit()
websites_html2 <- arrow::read_parquet("/run/media/knut/HD/MLearningAlgoTests/aicompanies_websites2") %>% na.omit()
websites_html <- bind_rows.(websites_html, websites_html2)
#adresses_extracted <-purrrgress::pro_map2_dfr(.x = websites_html$body, .y = websites_html$source, .f = safeparse)
adresses_extracted <- arrow::read_parquet("/run/media/knut/HD/MLearningAlgoTests/aicompanies_websites_adresses")
roads <- adresses_extracted %>% filter.(label=="road") %>% distinct.(source, value, label)
city <- adresses_extracted %>% filter.(label=="city") %>% distinct.(source, value, label)
kg_names <- read_parquet("/run/media/knut/HD/MLearningAlgoTests/data/polar/w5mentities.parquet") %>% separate.(label, c("selector", "disambiguation"), sep = "[(]") %>% mutate.(disambiguation=str_remove(disambiguation, "[)]"))
kg_names_locations <- kg_names %>% right_join.(cities%>% mutate(nchar=nchar(location)) %>% filter(nchar>3) %>% mutate.(selector=location)) %>% left_join.(kg_names %>% select.(wikientity, spelling=selector) %>% mutate.(spelling=str_squish(spelling))) %>% distinct.() %>% mutate(nchar2=nchar(spelling)) %>% filter(nchar2>3)
kg_names_locations[is.na(kg_names_locations$spelling),"spelling"] <- kg_names_locations[is.na(kg_names_locations$spelling),"selector"]
chinese_cities_spellings <- read_html("https://en.wikipedia.org/wiki/List_of_cities_in_China") %>% html_node("table.selected_now") %>% html_table() %>% select(location=City, spelling=Chinese) %>% mutate(location=tolower(location), country="China")
kg_names_locations <- kg_names_locations %>% select.(location, country, spelling) %>% bind_rows.(chinese_cities_spellings)
kg_names_locations <- kg_names_locations %>% distinct.()
city_confirmed <- city %>% mutate(value=tolower(value)) %>% inner_join.(kg_names_locations %>% rename(value=spelling)) %>% rename(spelling=value) %>% distinct.()
body <- websites_html%>% inner_join.(city_confirmed)
suffix <- body %>% mutate(suffix=urltools::domain(source) %>% urltools::suffix_extract())
suffix <- suffix$suffix$suffix
body <- body %>% mutate(suffix=suffix)
country_codes <- read_html("https://www.sitepoint.com/complete-list-country-code-top-level-domains/") %>% html_table("td", header = F, trim = T) %>% as.data.frame()%>% filter(X1%in%c(".ai", ".io", ".com")==F) %>% rename(suffix=X1, Country=X2) %>% mutate(suffix=str_remove(suffix, ".")) %>% mutate(Country=str_replace(Country, "People's Republic of China", "China")) %>% mutate(Country=str_replace(Country, "United States of America", "United States"))
ai_companies_no_proc <- fread("/run/media/knut/HD/MLearningAlgoTests/aicompanies.csv")
body_city <- body %>% left_join.(country_codes) %>% filter(country==Country) %>% distinct.(-body) %>% inner_join.(ai_companies_no_proc %>% select(source=website, company))
ai_companies_more <- bind_rows.(locations_filter%>% inner_join.(ai_companies_no_proc %>% select(source=website, company)), body_city)
ai_companies_more <- ai_companies_more %>% distinct(company, location, country, source) %>% as.data.frame() %>% filter(company%in%c("SIS Software GmbH", "JOBFIE", "Neurobotics", "Rai")==F, location%in%c("orange", "mobile")==F) %>% bind_rows.(ai_companies_more%>% filter(company%in%c("Neurobotics")==T) %>% filter(location=="moscow"))
ai_companies <- ai_companies %>% bind_rows.(ai_companies_more)%>% distinct(company, location, country) %>% as.data.frame()
ggcharts::bar_chart(ai_companies_more, country, top_n = 30)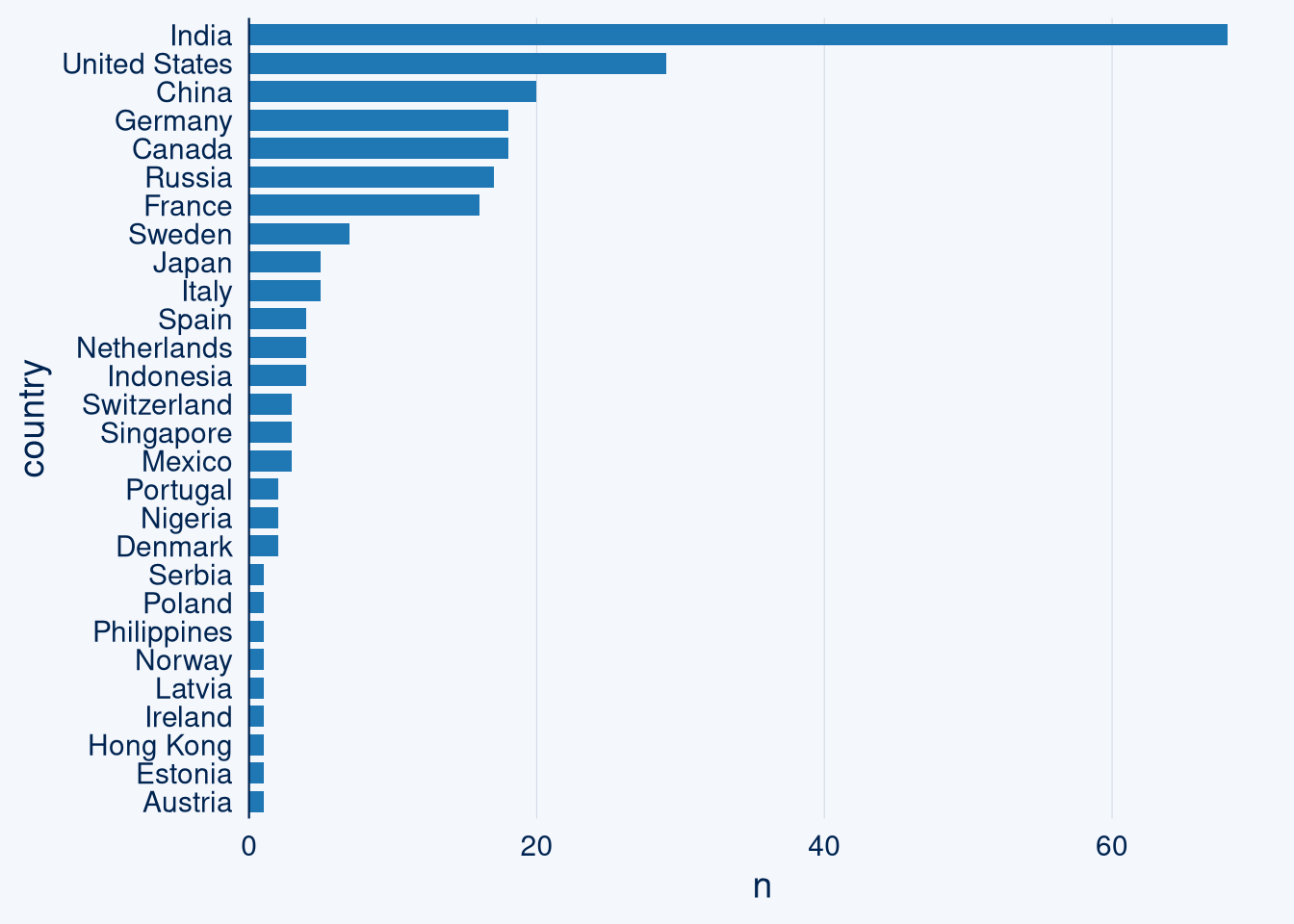
#roads_cities <- roads %>% inner_join.(adresses_extracted)Further datasets
I also collected two other datasets. Now we have to merge and deduplicate them.
ai_startups_europe <- openxlsx::read.xlsx("/run/media/knut/HD/MLearningAlgoTests/ai_startups.xlsx", sheet = 1)
ai_startups_world <- openxlsx::read.xlsx("/run/media/knut/HD/MLearningAlgoTests/ai_startups.xlsx", sheet = 2)
ai_startups_europe %>% sample_n(10)## Name Logo Website Country
## 1 Bodyguard.ai NA https://www.bodyguard.ai/fr France
## 2 Mobius Labs NA https://www.mobiuslabs.com/ Germany
## 3 Truphysics NA http://truphysics.com/ Germany
## 4 Canotic NA http://canotic.com/ Germany
## 5 Deepsense NA http://www.thedeepsense.co/ France
## 6 Keen Eye NA https://www.keeneyetechnologies.com/en/ France
## 7 Hallidai AI Gaming NA http://hellofridai.com/ Germany
## 8 Loop Robots NA https://looprobots.com/ Netherlands
## 9 Toposens NA http://toposens.com/ Germany
## 10 Pricefx NA http://www.pricefx.com/ Germany
## City Founding.Year Enterprise.Intell.
## 1 Nice 2017 Computer Linguistics
## 2 Berlin 2018 Computer Vision
## 3 Stuttgart 2014 <NA>
## 4 Berlin 2018 <NA>
## 5 Paris 2018 Computer Vision
## 6 Paris 2015 <NA>
## 7 Berlin 2018 <NA>
## 8 Delft 2020 <NA>
## 9 Munich 2015 <NA>
## 10 Pfaffenhofen An Der Glonn 2011 Discovery
## Enterprise.Func. Industry Technology.Type
## 1 <NA> Other Service Activities <NA>
## 2 <NA> <NA> <NA>
## 3 <NA> Manufacturing <NA>
## 4 <NA> <NA> Applications
## 5 IT & Security <NA> <NA>
## 6 <NA> Human Health & Social Work Activities <NA>
## 7 <NA> Arts, Entertainment & Recreation <NA>
## 8 <NA> Human Health & Social Work Activities <NA>
## 9 <NA> <NA> Infrastructure
## 10 Sales <NA> <NA>ai_startups_world %>% sample_n(10)## Country State City Name
## 1 United States Massachusetts Boston Adhark
## 2 Japan <NA> <NA> Kinpen
## 3 United States California Sunnyvale ThroughPut Inc.
## 4 United States New York New York Pymetrics
## 5 Israel <NA> Tel Aviv PhraseTech
## 6 Japan <NA> Fukuoka Next-System
## 7 Israel <NA> <NA> K.Y.C Int.
## 8 Canada Newfoundland and Labrador St. John's Afinin Labs
## 9 United Kingdom England London Behavox
## 10 China <NA> Shenzhen Prafly
## Category.-.Final
## 1 Computer Vision
## 2 Travel
## 3 Business Intelligence
## 4 Human Resources
## 5 Sales/Marketing
## 6 Software Development
## 7 Defense/Security
## 8 Core AI
## 9 Business Intelligence
## 10 Communication
## Description
## 1 Adhark is an image performance software company.
## 2 <NA>
## 3 Data Consultant Automation that helps supply chains run leaner.
## 4 Pymetrics is the next generation job marketplace.
## 5 <NA>
## 6 cutting-edge technology and utilizing the content, Provide the best service to society, the future society is rich in comfort and convenience for everyone and creating a corporate mission .
## 7 <NA>
## 8 Afinin Labs has a proprietary machine learning system that identifies and adapts to trends in the financial markets. The system generates buy/sell signals for targeted equities when it determines there is an opportunity for profit. Pioneered by experts in the field of machine learning and applied financial analysis, Afinin provides a trading algorithm unlike anything available in the marketplace. Backed by years of research excellence, the algorithm delivers a trading signal with a high level of prediction accuracy to the execution systems of hedge funds. Hedge funds realize an exceptional rate of return for investors by leveraging the algorithm for the management of a portion of their funds under management.
## 9 Behavox is an enterprise compliance software company which provides holistic employee surveillance solutions. The company's solutions allow Senior Management, Risk & Compliance Officers to detect cases of market abuse, insider threat, collusion and reckless behavior in real time.
## 10 <NA>
## Website
## 1 http://www.adhark.com/
## 2 https://info.kinpen.me/
## 3 https://throughput.world
## 4 https://www.pymetrics.com
## 5 https://www.phrasetech.com
## 6 http://www.next-system.com/eng/index.html
## 7 https://www.kycint.com/home
## 8 http://www.afinin.com
## 9 http://www.behavox.com
## 10 http://www.prafly.com/I use the reclin package for record linkage deduplication based on string edit distance (jaccard). For the first two datasets, there are only a few duplicates.
world_s <- ai_startups_world %>% select(company=Name, country=Country, location=City)%>% mutate(location=tolower(location))
europe <- ai_startups_europe %>% select(company=Name, country=Country, location=City)%>% mutate(location=tolower(location))
p <- pair_blocking(world_s, europe, large = FALSE)
p <- compare_pairs(p, by = c("company", "location", "country"))
p <- compare_pairs(p, by = c("company", "location", "country"),
default_comparator = jaccard(0.9), overwrite = TRUE)
p <- score_simsum(p, var = "simsum")
m <- problink_em(p)## Warning: `group_by_()` was deprecated in dplyr 0.7.0.
## Please use `group_by()` instead.
## See vignette('programming') for more help
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.p <- score_problink(p, model = m, var = "weight")
p <- select_threshold(p, "weight", var = "threshold", threshold = 18.94455)
p <- add_from_x(p, id_x = "id")
linked_data_set <- link(p) %>% na.omit()
linked_data_set## company.x country.x location.x company.y
## 1 Vyer Technologies Sweden stockholm LINKAI Technologies AB
## 2 SoftRobot Sweden uppsala SoftRobot Sweden AB
## 3 Aiir Innovations Netherlands amsterdam Aiir Innovations
## 4 Storyzy France paris Storyzy
## 5 Lili.ai France paris Lili.ai
## 6 LightOn France paris LightOn
## 7 Scibids Technology France paris Kili Technology
## 8 Shift Technology France paris Kili Technology
## 9 Calldesk France paris calldesk
## 10 Walnut Algorithms France paris Walnut Algorithms
## 11 Heuritech France paris Heuritech
## 12 Scibids Technology France paris Scibids Technology
## 13 Shift Technology France paris Scibids Technology
## 14 Doctrine France paris Doctrine
## 15 Beyable France paris Beyable
## 16 Scibids Technology France paris Shift Technology
## 17 Shift Technology France paris Shift Technology
## 18 Wiidii France bordeaux Wiidii
## 19 EasyMile France toulouse Easymile
## 20 Deepomatic France paris Deepomatic
## 21 Craft AI France paris Craft.AI
## 22 Sensewaves France paris Sensewaves
## 23 Clustaar France paris Clustaar
## 24 DreamQuark France paris DreamQuark
## 25 Ubiant France lyon Ubiant
## 26 Kayrros France paris Kayrros
## 27 SESAMm France metz SESAMm
## 28 Qynapse France paris Qynapse
## 29 Karos France paris Karos
## 30 Invenis France paris Invenis
## 31 Happyr Sweden stockholm Happyr AB
## 32 Unibap Sweden uppsala Unibap AB
## 33 Unibap Sweden uppsala Unibap AB
## 34 Greater Than Sweden stockholm Greater Than
## 35 Gleechi Sweden stockholm Gleechi AB
## 36 Univrses Sweden stockholm Univrses AB
## 37 Lexplore Sweden stockholm Lexplore
## 38 Imagimob Sweden stockholm Imagimob AB
## 39 Aaron Germany berlin Aaron
## 40 Ada Germany berlin Ada
## 41 parlamind Germany berlin Parlamind
## 42 Risk Ident Germany hamburg Risk Ident
## 43 Rasa Germany berlin Rasa
## 44 Bunch Germany berlin Bunch
## 45 Fraugster Germany berlin Fraugster
## 46 Inspirient Germany berlin Inspirient
## 47 Mapegy Germany berlin Mapegy
## 48 Lateral Germany berlin Lateral
## 49 Lateral Germany berlin Realrate
## 50 Cargonexx Germany hamburg Cargonexx
## 51 TwentyBN Germany berlin Twentybn
## 52 German Autolabs Germany berlin German Autolabs
## 53 Xbird Germany berlin Xbird
## 54 picsure Germany munich Picsure
## 55 Picsure Germany munich Picsure
## 56 micropsi industries Germany berlin Micropsi Industries
## 57 Micropsi Industries Germany berlin Micropsi Industries
## 58 Contiamo Germany berlin Contiamo
## 59 Explosion AI Germany berlin Explosion
## 60 SearchInk Germany berlin SiaSearch
## country.y location.y
## 1 Sweden stockholm
## 2 Sweden uppsala
## 3 Netherlands amsterdam
## 4 France paris
## 5 France paris
## 6 France paris
## 7 France paris
## 8 France paris
## 9 France paris
## 10 France paris
## 11 France paris
## 12 France paris
## 13 France paris
## 14 France paris
## 15 France paris
## 16 France paris
## 17 France paris
## 18 France bordeaux
## 19 France toulouse
## 20 France paris
## 21 France paris
## 22 France paris
## 23 France paris
## 24 France paris
## 25 France lyon
## 26 France paris
## 27 France metz
## 28 France paris
## 29 France paris
## 30 France paris
## 31 Sweden stockholm
## 32 Sweden uppsala
## 33 Sweden uppsala
## 34 Sweden stockholm
## 35 Sweden stockholm
## 36 Sweden stockholm
## 37 Sweden stockholm
## 38 Sweden stockholm
## 39 Germany berlin
## 40 Germany berlin
## 41 Germany berlin
## 42 Germany hamburg
## 43 Germany berlin
## 44 Germany berlin
## 45 Germany berlin
## 46 Germany berlin
## 47 Germany berlin
## 48 Germany berlin
## 49 Germany berlin
## 50 Germany hamburg
## 51 Germany berlin
## 52 Germany berlin
## 53 Germany berlin
## 54 Germany munich
## 55 Germany munich
## 56 Germany berlin
## 57 Germany berlin
## 58 Germany berlin
## 59 Germany berlin
## 60 Germany berlinThere were some duplicates in the scraped dataset. Getting rid of them here.
both <- world_s %>% bind_rows.(europe %>% filter(company%in%linked_data_set$company.y==F)) %>% distinct.() %>% na.omit()
p <- pair_blocking(ai_companies, ai_companies, large = FALSE)
p <- compare_pairs(p, by = c("company", "location", "country"))
p <- compare_pairs(p, by = c("company", "location", "country"),
default_comparator = jaccard(0.9), overwrite = TRUE)
p <- score_simsum(p, var = "simsum")
m <- problink_em(p)
p <- score_problink(p, model = m, var = "weight")
p <- select_threshold(p, "weight", var = "threshold", threshold = 10.95548)
p <- add_from_x(p, id_x = "id")
p <- p %>% filter(weight<16.40807)
linked_data_set <- link(p) %>% na.omit()
linked_data_set## [1] company.x location.x country.x company.y location.y country.y
## <0 rows> (or 0-length row.names)These are mostly literal matches.
ai_companies <- ai_companies%>% filter(company%in%linked_data_set$company.y==F)
p <- pair_blocking(ai_companies, both, large = FALSE)
p <- compare_pairs(p, by = c("company", "location", "country"))
p <- compare_pairs(p, by = c("company", "location", "country"),
default_comparator = jaccard(0.9), overwrite = TRUE)
p <- score_simsum(p, var = "simsum")
m <- problink_em(p)
p <- score_problink(p, model = m, var = "weight")
p <- select_threshold(p, "weight", var = "threshold", threshold = 9.959988)
p <- add_from_x(p, id_x = "id")
p <- p %>% filter(weight<16.40807)
linked_data_set <- link(p) %>% na.omit()
linked_data_set## company.x location.x country.x
## 1 Alitheia Technologies Inc. toronto Canada
## 2 Augmented Knowledge incheon Korea, South
## 3 Cochlear.ai seoul Korea, South
## 4 Dream Youngs seoul Korea, South
## 5 Driva - AI Dash Cam Driving Assistant shanghai China
## 6 Elektronik Virtual Asisten (EVA.id) bandung Indonesia
## 7 GoodAI prague Czechia
## 8 Granata Decision Systems toronto Canada
## 9 Internuncio Technologies Inc. vancouver Canada
## 10 MeasureChina seoul Korea, South
## 11 Moran Cognitive Technology beijing China
## 12 Omnious seoul Korea, South
## 13 Qualaris Healthcare Solutions pittsburgh United States
## 14 Riiid seoul Korea, South
## 15 SC5 (part of Nordcloud Group) helsinki Finland
## 16 Visual Camp seoul Korea, South
## company.y country.y location.y
## 1 Alitheia Technologies Inc. Canada toronto
## 2 Augmented Knowledge South Korea incheon
## 3 Cochlear.ai South Korea seoul
## 4 Dream Youngs South Korea seoul
## 5 Driva - AI Dash Cam Driving Assistant China shanghai
## 6 Elektronik Virtual Asisten (EVA.id) Indonesia bandung
## 7 GoodAI Czech Republic prague
## 8 Granata Decision Systems Canada toronto
## 9 Internuncio Technologies Inc. Canada vancouver
## 10 MeasureChina South Korea seoul
## 11 Moran Cognitive Technology China beijing
## 12 Omnious South Korea seoul
## 13 Qualaris Healthcare Solutions United States pittsburgh
## 14 Riiid South Korea seoul
## 15 SC5 (part of Nordcloud Group) Finland helsinki
## 16 Visual Camp South Korea seoulUnsurprisingly, this dataset will have some bias, but it should work fine to show AI hubs. Below how many companies come from the top 30 countries. The dataset contains more than 7k AI companies.
ai_companies_all <- ai_companies %>% bind_rows.(both %>% filter(company%in%linked_data_set$company.y==F)) %>% distinct.()
ggcharts::bar_chart(ai_companies_all, country, top_n = 30)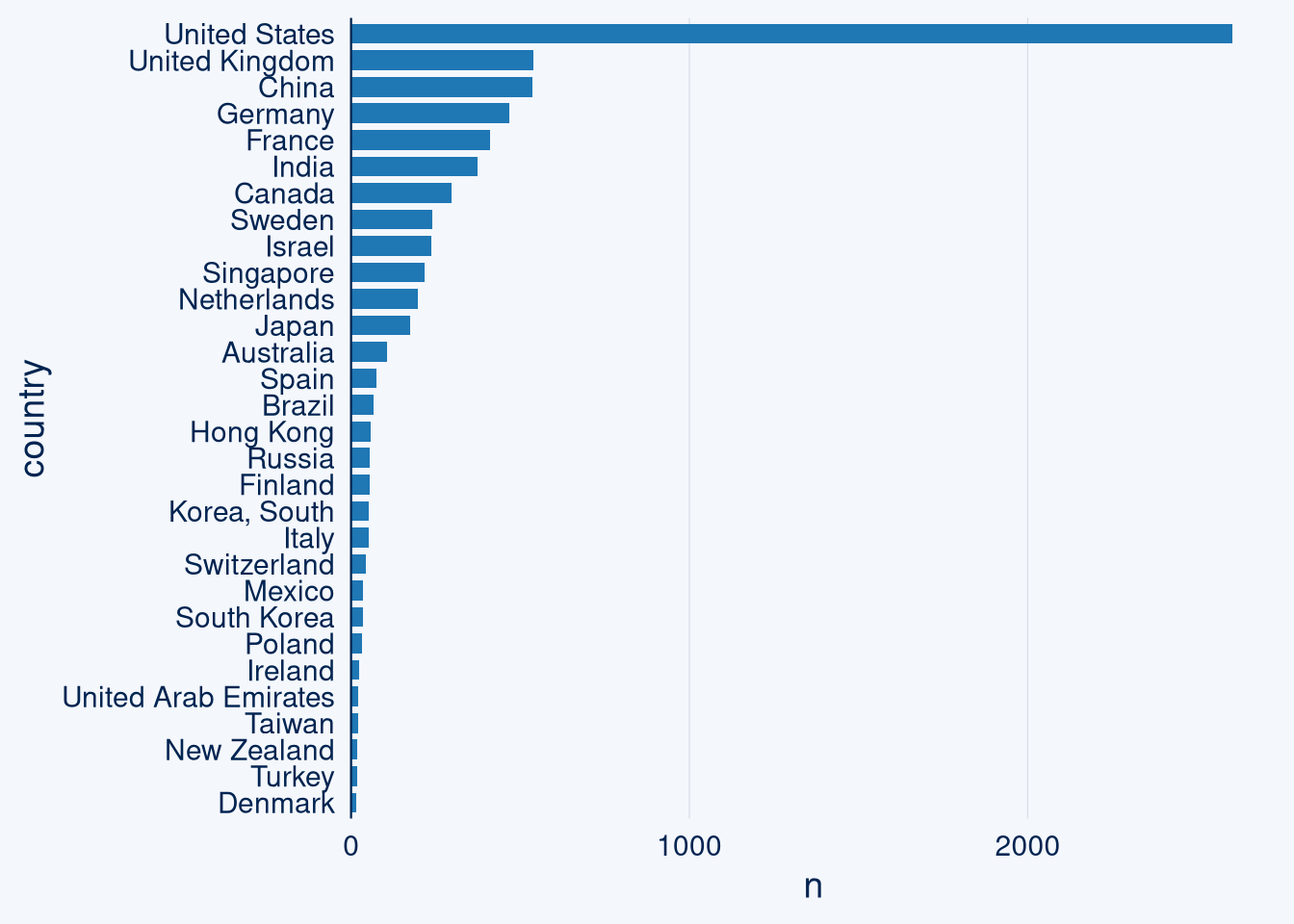
AI hubs around the world
ai_companies_per_city <- ai_companies_all %>% group_by(location, country) %>% count(sort = T)%>% rename(`Companies in City`=n) %>% mutate(country=str_replace(country, "United States", "USA"), large=ifelse(`Companies in City`>9, location, NA))
ai_companies_per_country <- ai_companies_all %>% group_by(country) %>% count(sort = T) %>% rename(`Companies in Country`=n)
World3 <- left_join(World, ai_companies_per_country %>% rename(name=country)) %>% ungroup()## Joining, by = "name"World3 <- st_sf(World3)
ai_cities <- world.cities %>% mutate(location=tolower(name)) %>% inner_join.(ai_companies_per_city, by=c("location"="location", "country.etc"="country")) %>% filter(location!="mobile")
cities <- ai_cities %>%
st_as_sf(coords = c("long", "lat"), crs = 4326) %>%
st_cast("POINT")
tmap_mode("plot")## tmap mode set to plottingai_hubs <- tm_shape(World3) +
tm_polygons(col = "Companies in Country", style = "fisher", palette = "-RdGy", n=10) +
tm_layout(legend.outside = F) + tm_shape(cities)+tm_bubbles(size = "Companies in City", col = "Companies in City", palette="Blues") + tmap::tm_style("grey")+ tm_text("large", size = "Companies in City")
ai_hubs## Note that tm_style("grey") resets all options set with tm_layout, tm_view, tm_format, or tm_legend. It is therefore recommended to place the tm_style element prior to the other tm_layout/tm_view/tm_format/tm_legend elements.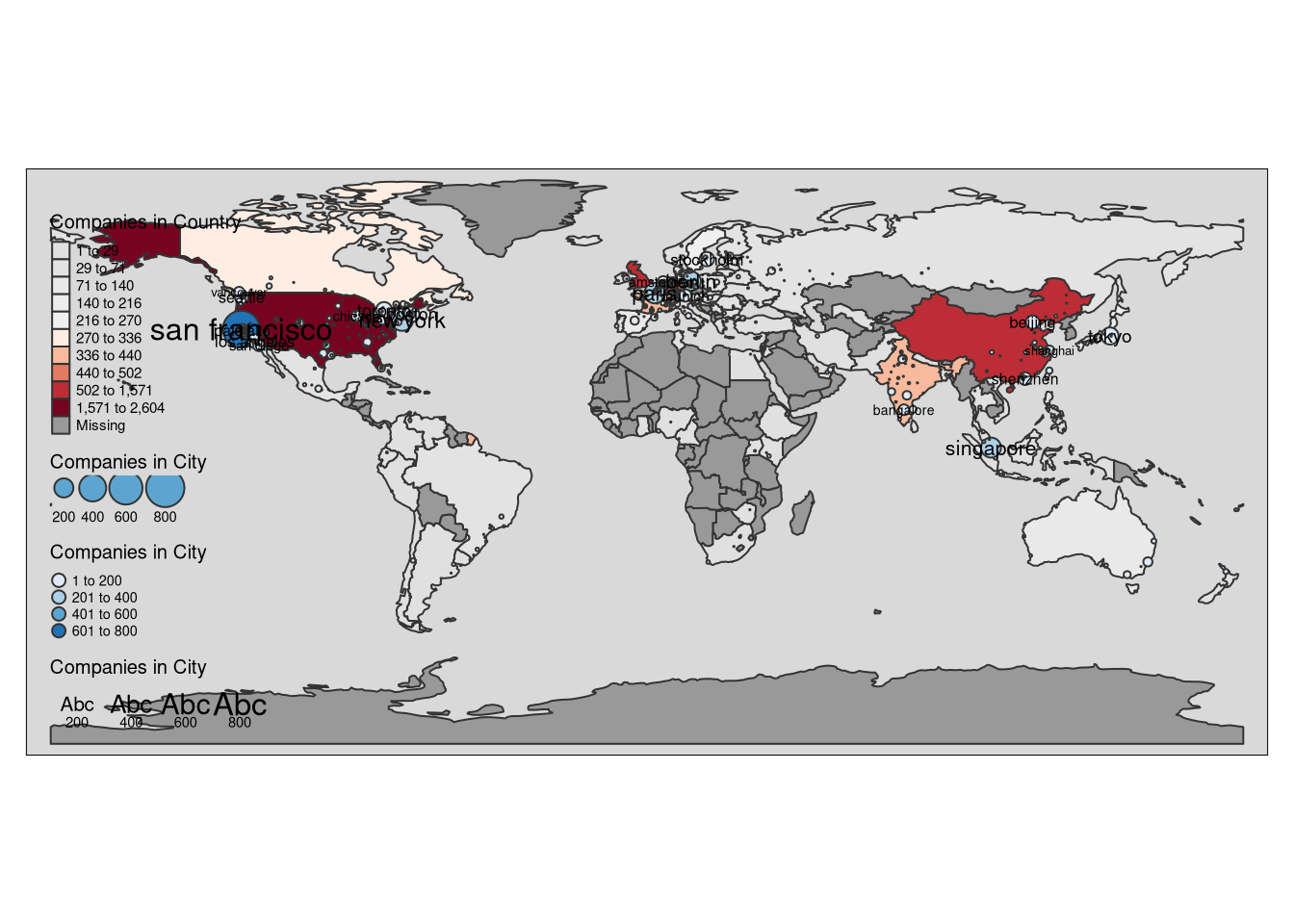
library(sf)
north_america <- st_bbox(cities %>% filter(country.etc %in% c("USA", "Canada", "Mexico")))
tm_shape(World3, bbox = north_america) +
tm_polygons(col = "Companies in Country", style = "fisher", palette = "-RdGy", n=10) +
tm_layout(legend.outside = F) + tm_shape(cities)+tm_bubbles(size = "Companies in City", col = "Companies in City", palette="Blues") + tmap::tm_style("grey")+ tm_text("large", size = 0.5)+ tm_legend(show=FALSE)## Note that tm_style("grey") resets all options set with tm_layout, tm_view, tm_format, or tm_legend. It is therefore recommended to place the tm_style element prior to the other tm_layout/tm_view/tm_format/tm_legend elements.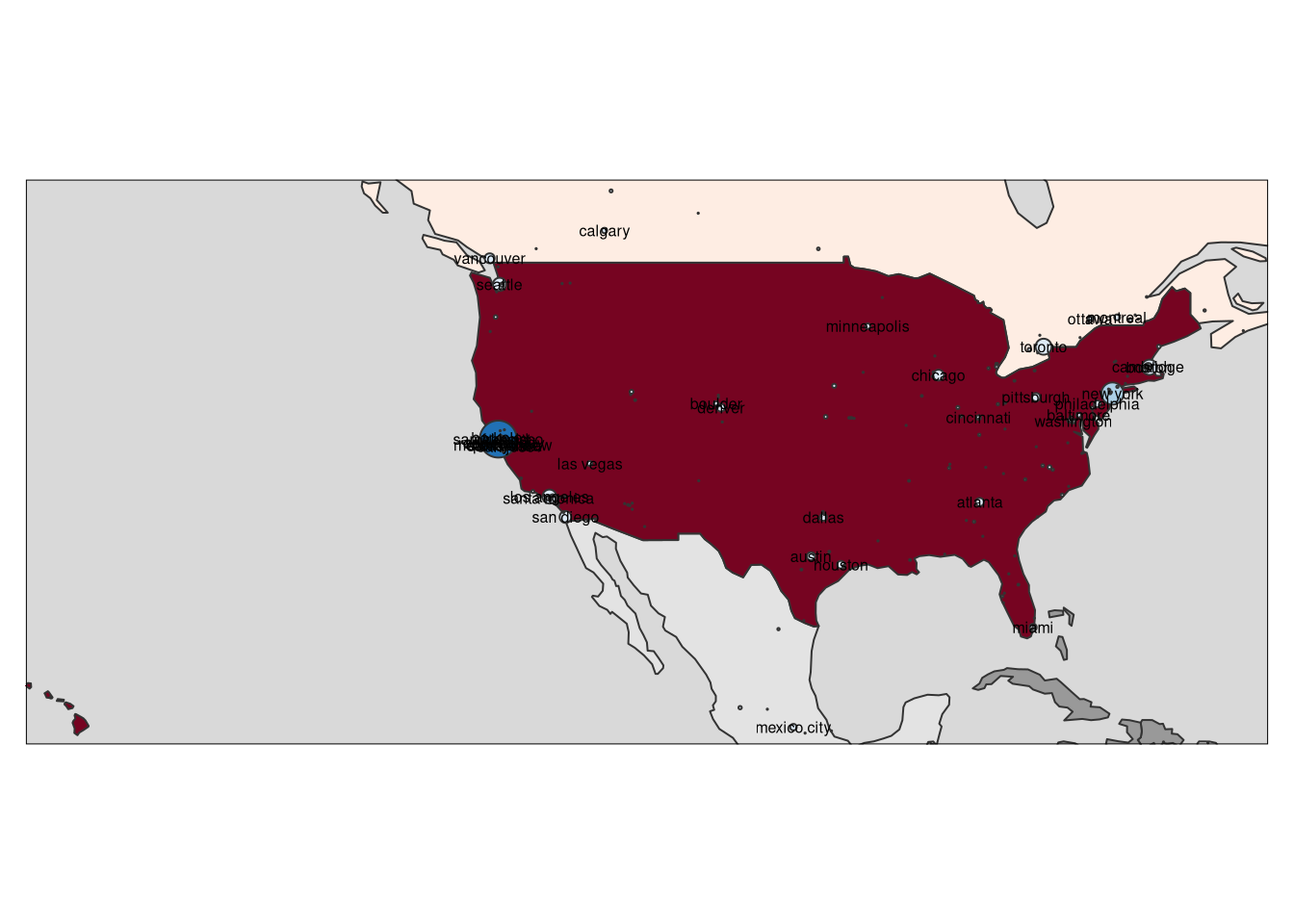
Hubs, hubs almost everywhere
europe <- st_bbox(cities %>% filter(country.etc %in% c("Spain", "Finland", "Turkey", "Ireland")))
tm_shape(World3, bbox = europe) +
tm_polygons(col = "Companies in Country", style = "fisher", palette = "-RdGy") +
tm_layout(legend.show = F) + tm_shape(cities)+tm_bubbles(size = "Companies in City", col = "Companies in City", palette="Blues") + tmap::tm_style("grey")+ tm_text("large", size = 0.5)+ tm_legend(show=FALSE)## Note that tm_style("grey") resets all options set with tm_layout, tm_view, tm_format, or tm_legend. It is therefore recommended to place the tm_style element prior to the other tm_layout/tm_view/tm_format/tm_legend elements.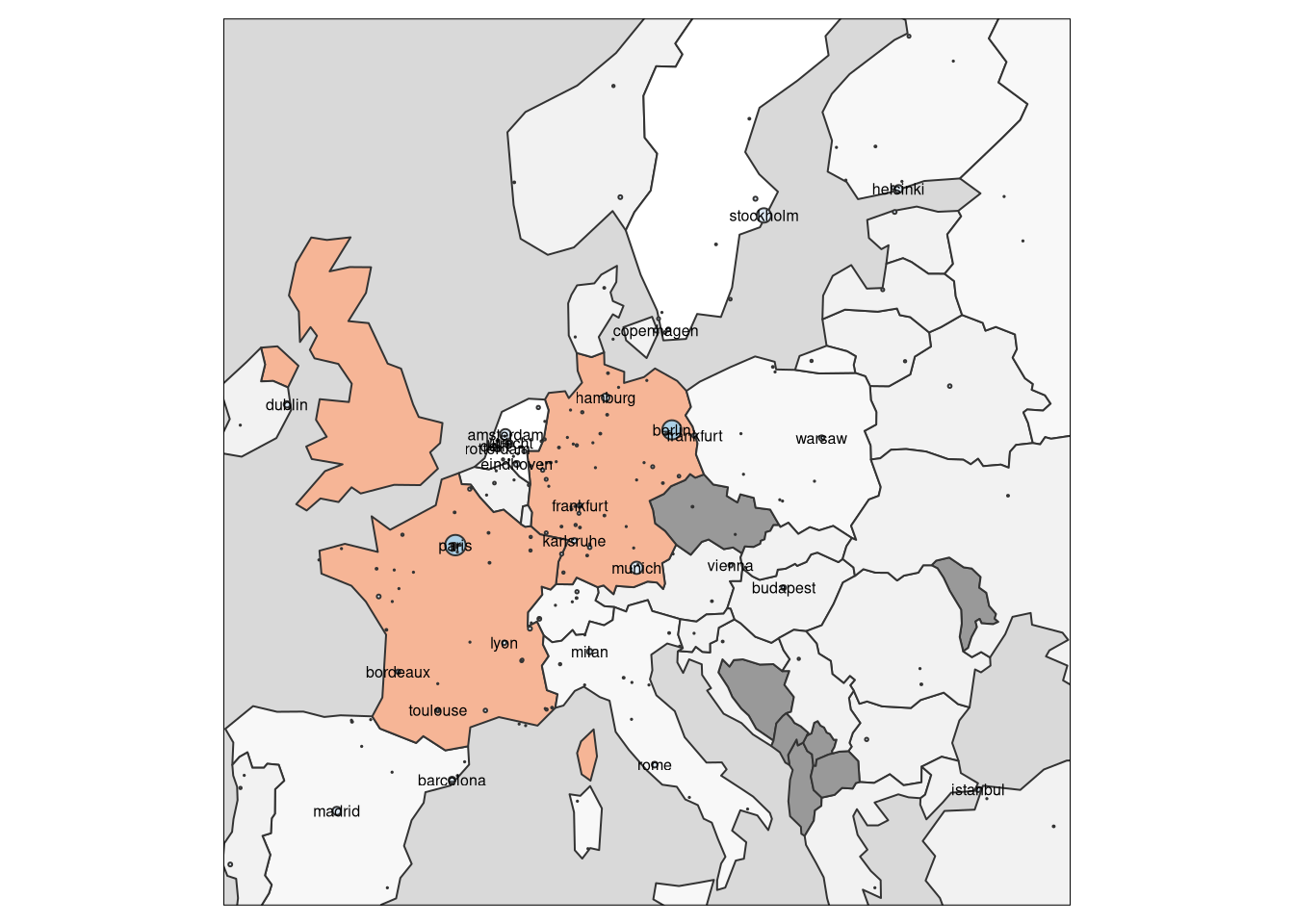
east_asia <- st_bbox(cities %>% filter(country.etc %in% c("China", "Japan")))
tm_shape(World3, bbox = east_asia) +
tm_polygons(col = "Companies in Country", style = "fisher", palette = "-RdGy") +
tm_layout(legend.show = F) + tm_shape(cities)+tm_bubbles(size = "Companies in City", col = "Companies in City", palette="Blues") + tmap::tm_style("grey")+ tm_text("large", size = 0.8)+ tm_legend(show=FALSE)## Note that tm_style("grey") resets all options set with tm_layout, tm_view, tm_format, or tm_legend. It is therefore recommended to place the tm_style element prior to the other tm_layout/tm_view/tm_format/tm_legend elements.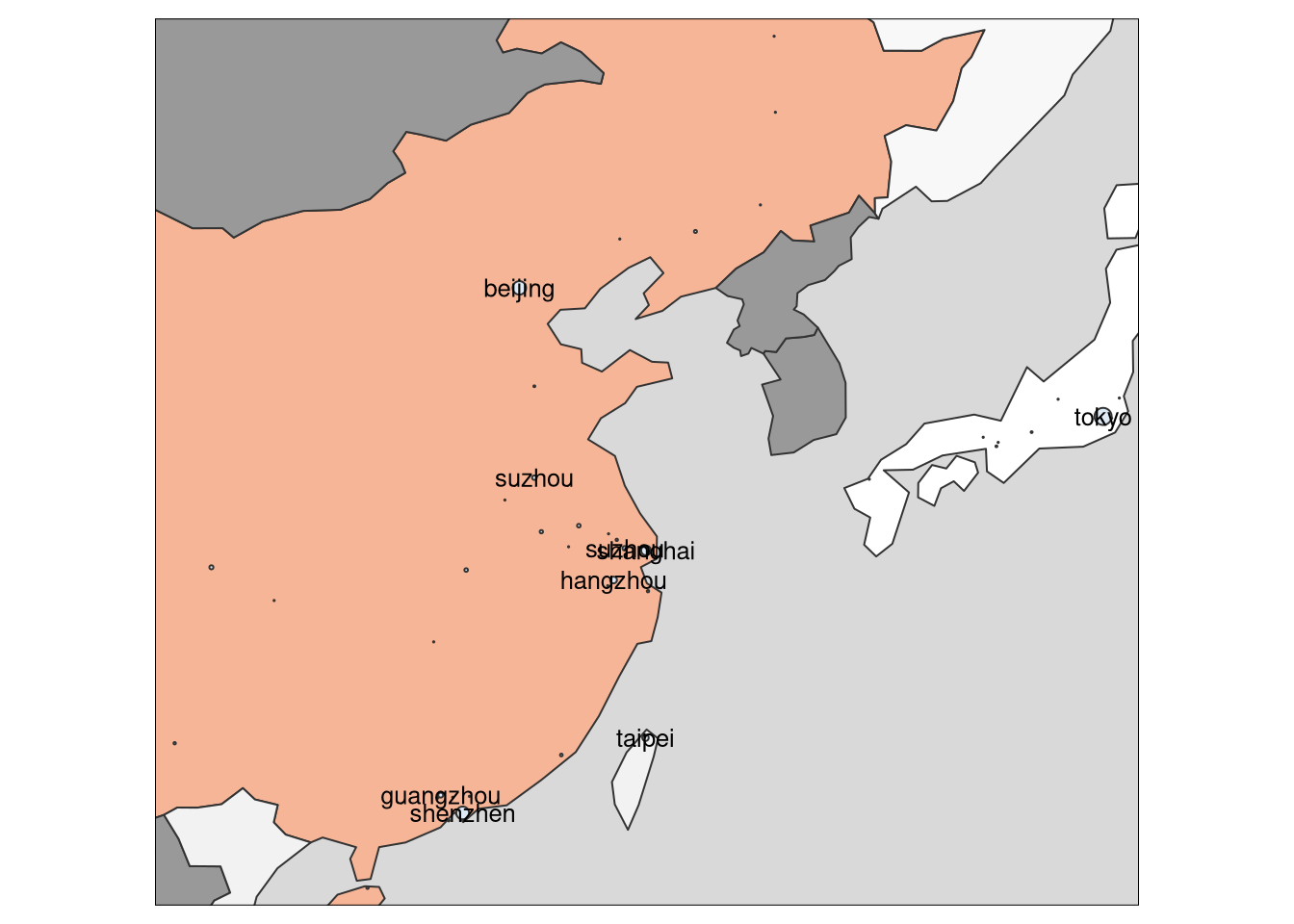
india <- st_bbox(cities %>% filter(country.etc %in% c("India")))
tm_shape(World3, bbox = india) +
tm_polygons(col = "Companies in Country", style = "fisher", palette = "-RdGy") +
tm_layout(legend.show = F) + tm_shape(cities)+tm_bubbles(size = "Companies in City", col = "Companies in City", palette="Blues") + tmap::tm_style("grey")+ tm_text("large", size = 0.8)+ tm_legend(show=FALSE)## Note that tm_style("grey") resets all options set with tm_layout, tm_view, tm_format, or tm_legend. It is therefore recommended to place the tm_style element prior to the other tm_layout/tm_view/tm_format/tm_legend elements.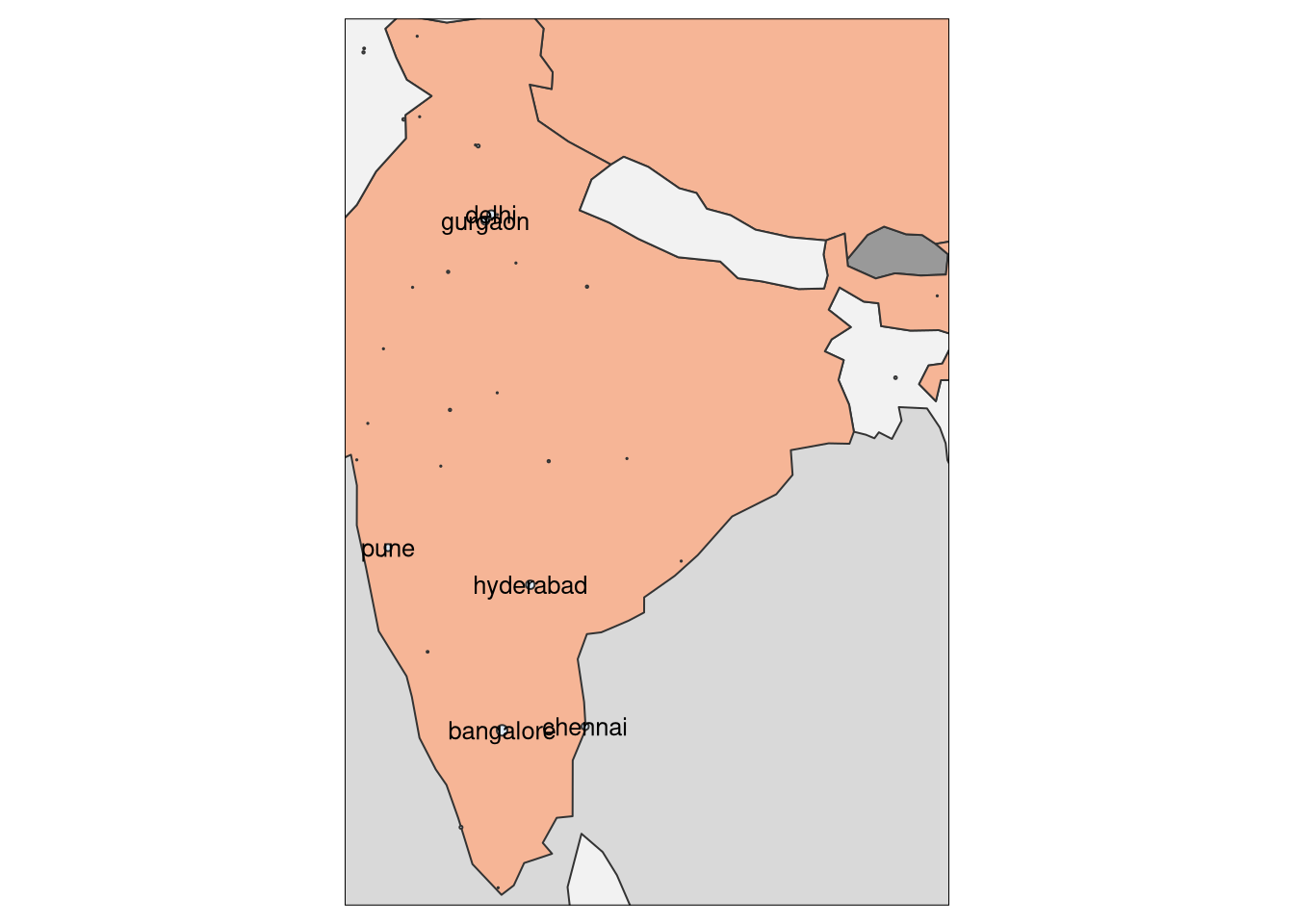
And the table itself.
ai_companies_all## # A tidytable: 7,357 × 3
## company location country
## <chr> <chr> <chr>
## 1 Hong Jing Drive hangzhou China
## 2 Gritworld shanghai China
## 3 Anruan Keji shenzhen China
## 4 Jiangsu Fant Technology hong kong Hong Kong
## 5 Hebin Intelligence hefei China
## 6 Lvzhou Technology hefei China
## 7 Fantai AI shanghai China
## 8 ccvui.com hangzhou China
## 9 Intengine Technology beijing China
## 10 CAIWA Service tokyo Japan
## # … with 7,347 more rowsCould be more could be less ;)